指南⚓︎
指南这部分文档将介绍 BaiduSpider 绝大多数函数的使用方法。
下面列出了一些通用文档。
搜索返回值⚓︎
BaiduSpider 的所有搜索函数都是一个自定义结果类。例如,PC端网页搜索返回类型为WebResult,而移动端网页搜索则为mobile.WebResult。
对于不同的搜索类型,BaiduSpider 提供不同的返回结果。更详细的返回类型请参考 API 文档。
代理设置⚓︎
几乎所有的 BaiduSpider 搜索函数都支持proxies参数。该参数的作用为设定代理 IP。下面是它的一些使用场景:
- 做数据分析,需要爬取大量数据时
- 人工智能无监督学习时
- 通过百度搜索进行特定的大量定时任务时
- 大量,频繁地搜集热点新闻时
- ……
由于用户的种种需求,我们特开发出了此功能。
该参数接受一个dict对象,例如:
from baiduspider import BaiduSpider
from pprint import pprint
spider = BaiduSpider()
result = spider.search_news(
"搜索词",
proxies={
"http": "http://192.168.xxx.xxx", # HTTP代理IP地址
"https": "https://192.168.xxx.xxx" # HTTPS代理IP地址
}
)
pprint(result.plain)
该功能的原理为设定requests.get函数的proxies参数,BaiduSpider仅提供了一个接口。由此,更详细的说明请参考requests文档。
请求过多怎么办?
如果遇到单个 IP 请求过多的话,可以使用 IP 代理池轮换使用。或者可以参考设置 Cookie 来延缓封禁。
Warning
此功能仅为学习和研究使用,请勿使用此功能爬取百度大量数据,违者后果自负。BaiduSpider 不为此功能承担任何法律责任。
出现解析警告⚓︎
请参考 FAQ。
设置Cookie⚓︎
BaiduSpider提供设定用户的Cookie来延缓被百度IP封禁的问题。目前仅支持 PC 端网页搜索,且不保证100%有效。
除此以外, PC 端文库搜索在搜索范围为“免费”("free")时,也需要传入Cookie才能进行正常搜索。
只有在登录了百度账号时获取的 Cookie 才能正常使用,未登录情况下无效。
Todo
移动端爬虫BaiduMobileSpider尚未开发此接口,请勿使用1。后期可能会考虑加入此接口。
你需要把你的 Cookie 传给 BaiduSpider,方式如下:
from baiduspider import BaiduSpider
# 在实例化BaiduSpider对象时传入cookie
spider = BaiduSpider(cookie="你的cookie")
然后,BaiduSpider 会在每次调用search_web的时候根据你的 Cookie 重新生成新的 Cookie 并稍加更改。
如何获取你的Cookie⚓︎
首先,打开你的浏览器并访问https://www.baidu.com/s?wd=placeholder&pn=0:
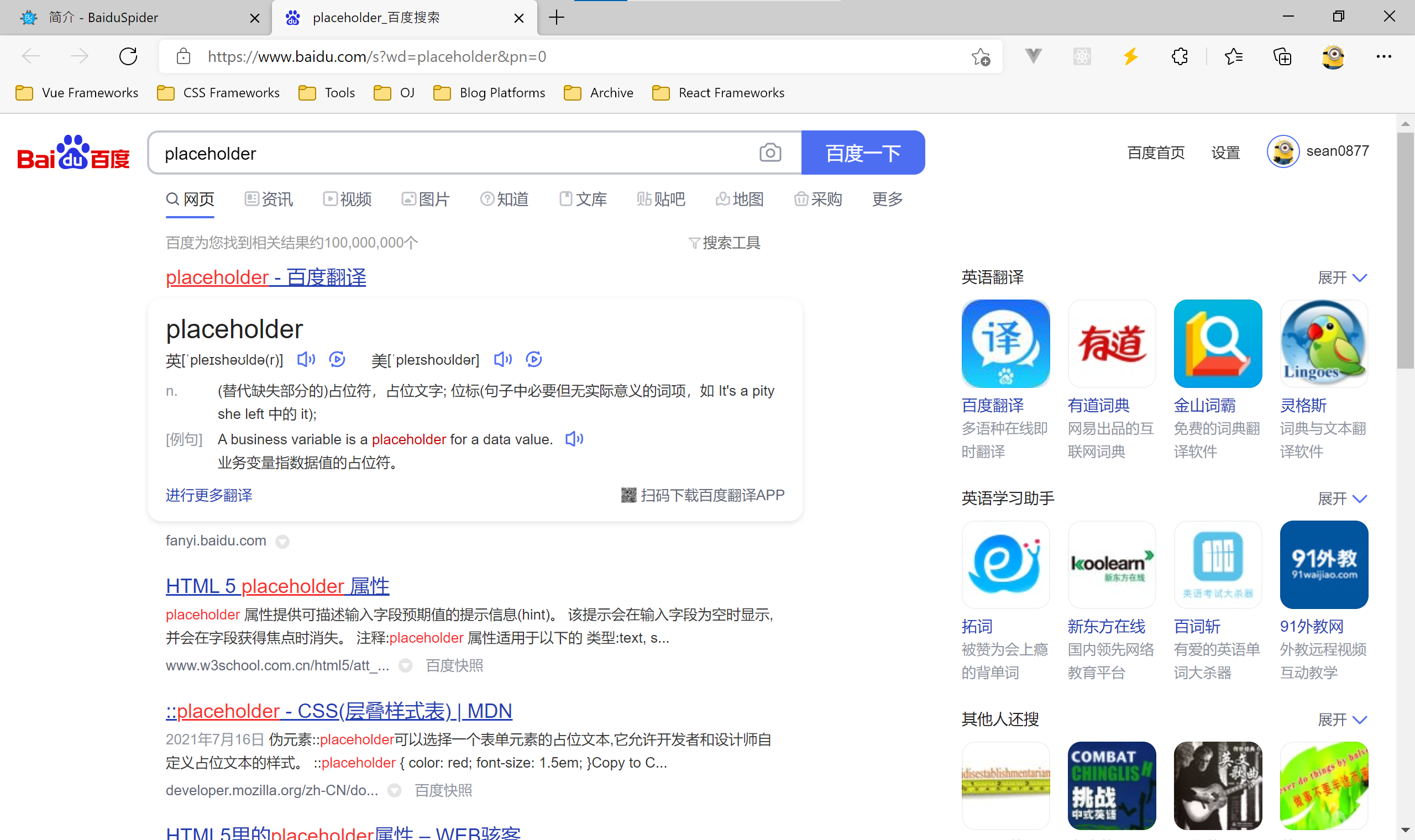
然后,按下 ++F12++ 打开开发者工具,并在开发者工具顶部选项栏中选择“网络”(Network)选项并按 ++Ctrl+r++:(Windows)或 ++Cmd+r++ (Mac)重新加载网页。开发者工具中将会显示一串列表,表示所有的请求。
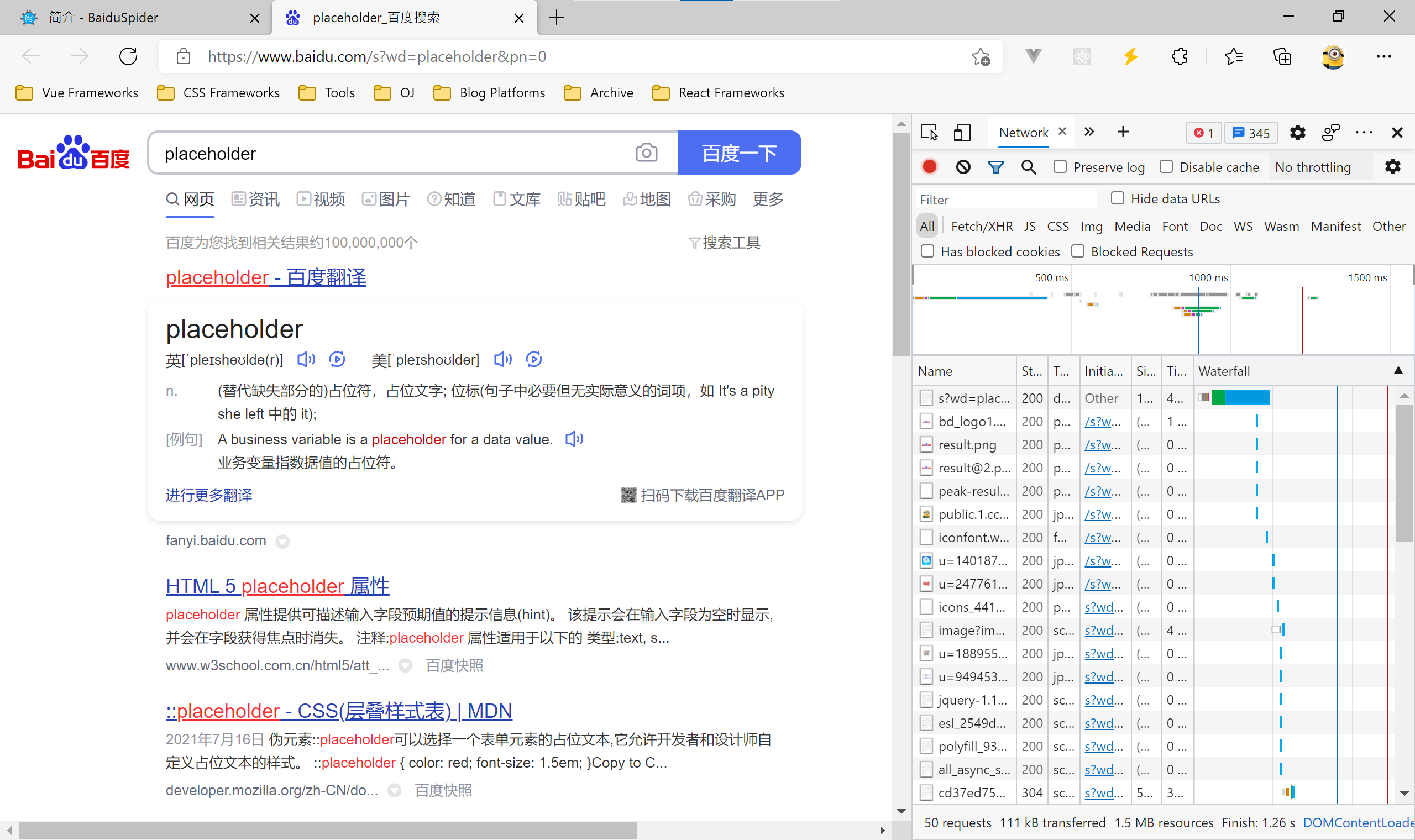
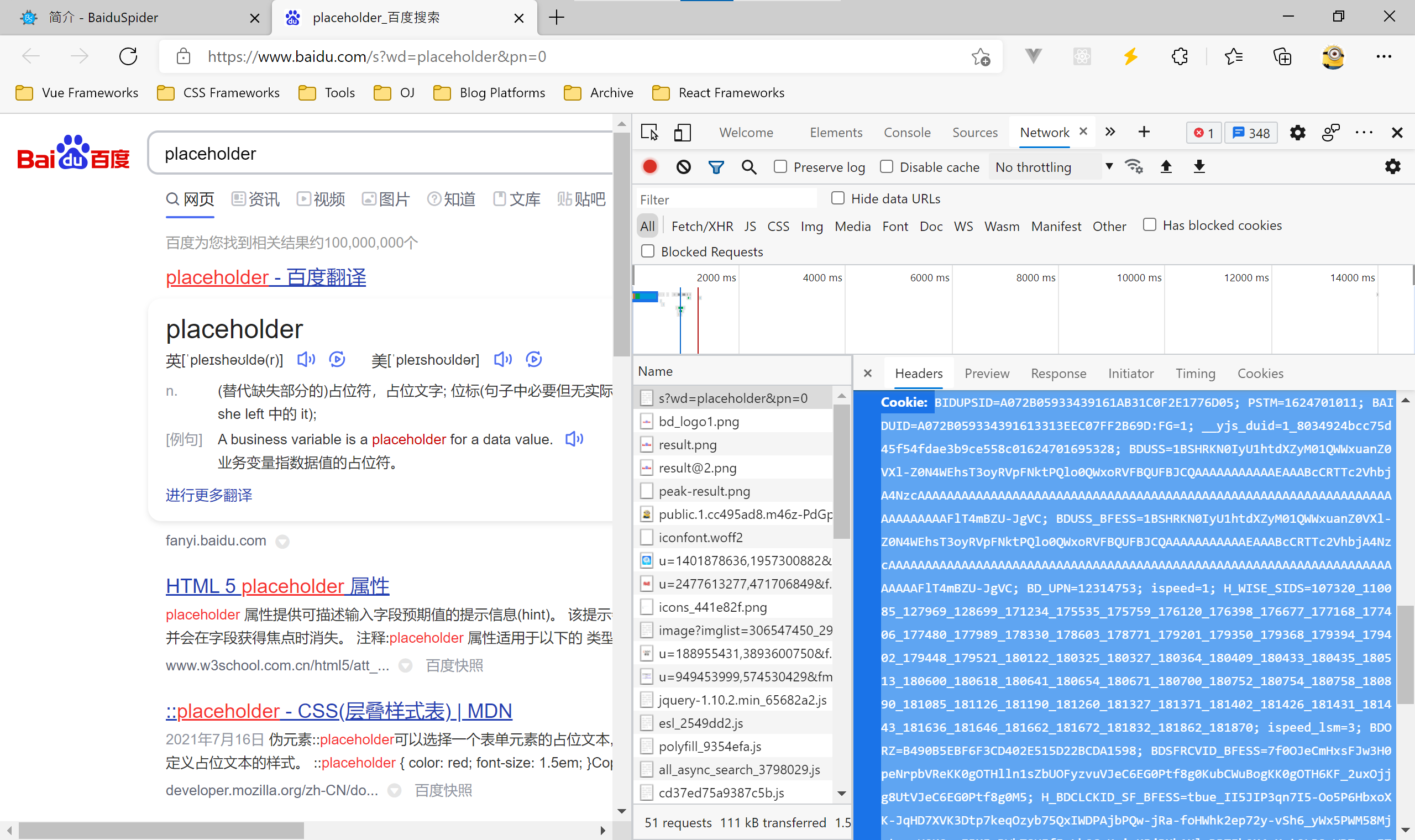
最后,在列表最上方点击以s?wd=placeholder开头的选项,将会弹出一个信息框。在信息框内的Headers(第一个)选项内找到Request Headers(请求头),再在Request Headers内找到 Cookie:,复制 Cookie 下的全部内容(不包括Cookie:),这就是你的 Cookie。
不要传入非法 Cookie!
请勿传入非法的 Cookie 给 BaiduSpider。这可能会导致错误,但更重要的是可能会使你的 IP 长时间封禁!
Warning
BaiduSpider 的这个功能仅供学习与研究,任何非法爬取百度大量数据的行为后果自负,BaiduSpider 开发团队不承担任何法律责任。
-
即
BaiduMobileSpider类暂时没有cookie参数,若使用会出现错误。 ↩